So far I’ve written a few blog posts around conducting RCAs where I’ve focused on the people and questions. However what I’ve yet to touch upon is the documentation side.
In a similar idea to the concept that the activity of coming up with a test plan is more important than the document itself, I have similar thoughts with the RCA. With this in mind, the most detailed document that I’d have is the collaboration board that I’ve used to facilitate the discussion. It captures our thoughts, discussion and key point.
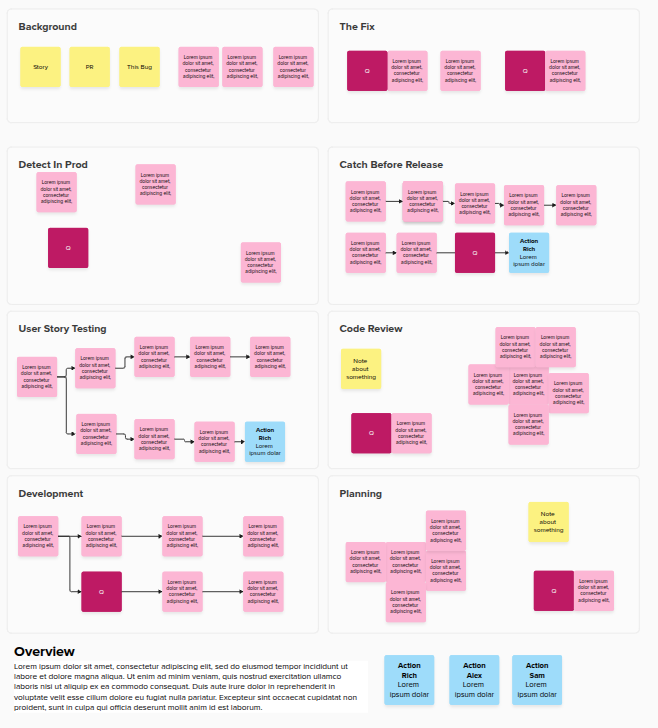
Example of a RCA, although this is all lorem ipsum text as I obviously can’t share a real one!
After the session I will then (as soon as possible) write up the overview. This is to capture the key findings from the RCA, explaining the nature of the problem, what we’ve learnt, any actions and so forth. This is shared with the team(s) on Slack to have a first look before I’d share it more widely.
I did like keeping a spreadsheet with my RCA findings. It would include the summary, a link to the board & tickets and an overly simplified “category” (missed requirement, domain knowledge, coding error etc).
This category is useful for metrics to help us understand patterns. This was useful when I was pushing to drive new initiatives because I could say “if we’d been using examples in refinement, we wouldn’t have had these massively complicated bugs”. If I’d had more time with my former employer, I’d have loved to explore a means of saving RCA summaries where I can tag the RCAs with different things to help demonstrate patterns.
I had also dabbled with feeding this data to an AI agent (one where we’d got the legal protections that it wouldn’t feed back into the main models). This was quite neat… but a topic for another day…
One final note is that I am aware that most people would still prefer to use a more formal & structured documentation approach than myself. I get that. Some of the things recorded could I guess be useful. However I’ve yet to experience any time where a 2 page document is useful. I have found these RCA discussions really useful and subsequently my documentation approach is similar to my retro approach. It is collaborating & capturing a conversation.
If you’d like to read more on RCAs, check out the collection of my posts on the Meaningful RCAs page!
I’ve already talked about how we need to tap into unleashing our inner toddler by asking “why”. But what questions do we ask?
Background
Before getting into the guts of the RCA I like to go through the background. This is partly to act as a refresher for everyone as it may have been a few weeks but also it will help guide me in my questioning.
This usually means sharing:
Links to the defect we’re RCAing & the original ticket
Links to PRs to fix the issue and where possible the original (“offending”) PR.
Then asking:
Can you describe the problematic behaviour? (i.e. what was actually wrong from a user’s point of view)
Can you describe the describe the nature of the code fix?
What do you remember from working on the story?
How long did it take?
How many people were involved?
The Fix
Before learning more about why the issue came to be, let’s make sure that we’re confident in the fix. I like to ask two questions here:
How resilient is the fix?
Will we know if the behaviour regresses again? (i.e. did you add automated tests)
Quality Engineering Throughout The SDLC
Now we get into the real important questions. This is where we go through the software development life cycle and think about what we did and whether there were opportunities to (realistically) catch it then.
First of all, if this was an escape, lets ask if we could have caught it in production (e.g. monitoring), release testing or epic close off testing. I wouldn’t advocate for just asking “could have have caught it here?” but asking around what the process is, what was the testing performed and is this something in the scope of what we’d usually test?
We then move on to the story within the sprint, starting with testing of the original story / bug. We’re trying to understand whether this was a brain fart (it happens) or is it just something that we wouldn’t usually consider testing? If not, why not?
Then we get into more technical. We’re looking at the PR, starting with code review. I’ll be asking about the nature of the bug and is that something that we’d look for? I’d want to understand whether SMEs were involved & if not, why not? Did they check the testing notes & automated tests in the code review? Code reviews aren’t ever going to catch everything but it is good to discuss this process. It is a nice chance for people to get to talk about the value and role of a code review too.
I then concentrate on the developer’s testing. What had they covered through automated and hands on tests? How much was iterative? As a former dev, I know all too well how even a well intended developer who tests their work can let things come through here (see dev BLISS).
We’re back then to technical discussions on the code. This is where I hope the architect can ask a few questions, although regularly other team members often chip in. This discussion is a great way for the team to learn from each other.
You might think that now that we’ve talked about the types of testing and the development challenges that we may stop there, but no we don’t!
The teams will have planning and refinement when we’re breaking down the story. We do test strategies and planning at epic and sometimes user story level. We think about the complexity of the code work with architectural studies before starting an epic. Let’s continue diving into these.
Again we’re asking about what was done, whether this is a scenario that could have been caught, either behaviour wise or in code, and tapping into what more we could have done. This helps us with spread left.
A Parting Question
Near the start I asked about our confidence in catching this issue again. Unless we’re running out of time (unfortunately often), I like to ask a similar but slightly wider question. How confident are we that we won’t see a repeat of the issue? Not necessarily the same issue but a similar one.
Summary Section
Finally I’ll have a summary section with actions, learnings and a summary of the RCA. Often written up afterwards because unsurprisingly the hour I book for RCAs isn’t always enough to cover everything in this post! I’ll explain a little more on this in a separate post.
So in short…
We start off by discussing the background of the story to refresh ourselves and help us get an idea on what threads are best to pull on as we go into things. We’ll also check we’re confident in the fix.
We then take our time going through the SDLC. We’re not just asking “could we have caught it?” or “why didn’t we catch it?” but looking at the actions, steps and processes to understand the answer to this.
I switched the ordering from starting with the first stages of the story to starting in prod after advice from a great chap called Stu Ashman. I found this got us much more engagement in some of the testing and activities around post release. You’ll also see how through the different stages we are asking slightly different questions to consider more than “why didn’t we catch it?”.
We’re using every stage as a learning opportunity.
I love collaboration and making exercises something that people can engage with. It is usually the discussion that matters more than what gets written on paper. For this to be successful, you need to have the right people in the (virtual) room.
As we’ve touched upon already, the RCA should touch upon all areas of the lifecycle of the source of the defect. Consequently I’d invite:
At least one person involved in refinement
The developer for the original story/defect
The code reviewer for the original story/defect
The tester for the original story/defect
The developer who fixed the defect that we’re doing the RCA for
An architect, even if they’ve no involvement before (arguably better). Failing that, a team lead.
Optionally any other team members.
I would have liked to invite a PO to some but I never got quite that bold.
There’s two things to highlight here.
First is that we’re focusing on who was involved when the defect was introduced. We have insight from the person who understands the fix but it is the processes, decisions and challenges in that original issue that we want to understand.
Secondly, with the architect and myself we have a cracking blend of insight. There’s someone who can analyse the code, design and technical side & ask meaningful questions and I can look at testing, process and examine ways of working.
For this to be successful you need all participants bought into the idea of being a safe place & no blame to be placed. I’ve written about this previously.
I did my first RCA back in 2019. We looked at each stage of development and used a “5 whys” approach to tap into why it wasn’t caught at this stage. We maintained this approach over the next few years and when I switched to my more coaching/leadership role in 2023, I started running them with the teams that I supported. We actually used Google Sheets or Excel for these. I’d have my bunch of questions to ask then I’d be asking the question then “why” to the answer. For example:
“During refinement did we call out our support for different browsers”
Nope, we should have
“Why wasn’t it raised? Tell me about your refinement”
Well we look at the high level requirements and turn that into ACs. We don’t look at more non-functional aspects.
“Why not?”
That is for the story’s test plan I guess.
“Why does this only impact testing and why isn’t that part of the estimate?”
… and so on
The point I’m trying to make in the fictional example above is that rather than just taking that first answer, you tap into it more to understand the real reason why the issue happened.
To help with asking questions, I like to lean on my ignorance – even if I had actually done my homework. It is more powerful to get someone to explain their problem or have to articulate what they did than you saying X & Y was done but not Z. This is why despite having read the ticket several times by now and dived through Slack conversations, I’ll ask who worked on it. I’ll ask whether everything went OK. I’ll ask whether topics like this came up in review.
My point here is I’m not running the RCA to have an answer to “why did this bug come to be” but so that we can discuss it and learn from it. This is what makes an RCA meaningful.
In time I’ve adapted and improved my questions, including the order that I ask them… but I’ll cover more in a subsequent post.
I’m currently writing about RCAs in a series of posts. If you aren’t familiar with them, check out my Meaningful RCAs page first.
One of the key things that I would emphasise before every RCA is that there needs to be either zero blame or full org blame. As I’ve written before, it takes a team to ship a bug, and the reason why we have refinement, unit tests, static analysis tools, code review and hands on testing is to catch such issues. If one person can truly be responsible for shipping a bug – that is your problem.
So why is it important that we have an open safe space and zero blame culture? Well if we want to truly tap into what happened and understand the chain of decisions that led to a mistake, we need to be able to talk about them. If people fear repercussions then how can they be expected to be open and honest? Whether that is disciplinary or more likely, just the social awkwardness of having your mistakes discussed.
However mistakes are part of software development and they will always occur. Tools & processes help us reduce the likelihood. We have our ways of working to help us build software correctly but they will sometimes have gaps or fail us. Sometimes that is fine. Shit happens. Bugs will happen. Sometimes we just need to accept this. But other times we can understand why something failed and improve it.
To help with this I like to share a little blurb at the start. I’ll joke about it requiring a team. I’ll make a point that this isn’t about blaming anyone and mistakes will happen. It is that mix of people, process and tools. Fixing the fallibility of human nature isn’t possible but fixing processes & improving tool usage is.
I also have about 17 years experience in a variety of different roles and experience of screwing up in a variety of exciting and new ways. I’m not ashamed of having made many mistakes down my career – it is natural – and if sharing that makes it a more open & safe space.
So when you’re running your RCA, or in the invite, share that it is zero blame. Share that we’re it is the process that we are interested in.
Software development is tricky. It can involve complicated tools, languages, domain spaces and a variety of teams & roles. The world in which we work is constantly changing and evolving and we need to adapt. On top of that, knowing best working practices isn’t instinctive like shark hunting or bird migration patterns. We need to learn. Just because your ways of working was fine on one project, it doesn’t mean it’ll work on the next or in a new scenario.
We all know about the idea of learning from mistakes.
“The only real mistake is the one from which we learn nothing” — Henry Ford
“Mistakes are the portals of discovery” — James Joyce
Within the world of software, arguably the best was to learn from our mistakes is through root cause analysis of escalations or high priority / worrying defects. Whilst some people may have done RCAs to conclude “missing test case” or “incorrect null handling”, meaningful RCAs are about learning why we made the mistakes and what we can do to avoid them… because this won’t be the last time that we miss test cases and incorrectly handle null.
Over my next few blog posts I’ll share how we can go about running meaningful RCAs to help us improve our ways of working to allow us to avoid being bitten twice and help build better quality software.
For more on RCAs, you can find a summary of what I’ve shared on my Meaningful RCA page.
The importance of developing secure software is (hopefully) understood but what about our working practices?
Many, if not most of us will be familiar with navigating IT restrictions. Firewalls, limits on what you can install or automatically deleting anything that isn’t digitally signed from an approved source. All these impediments to us working.
Perhaps, like myself, you’ve disabled some security measures in the past as a quick measure to get a short test running. Or you run things as admin rather than setting up nuances permissions. Perhaps you’ve used your personal device to read a file.
Let me introduce CD Projekt Red. On the back of a rather stormy launch to Cyberpunk 2077 they were hacked. From what I gather, all their source code was stolen, personal employee data stolen and machines were encrypted with ransomware.
But this can’t happen to you right? Well maybe it could.
A couple of years ago I was working from home using a mixture of my own computers and CCTV cameras and also work kit on loan. One of my personal devices was compromised and at the time I panicked a little, re-imaged it and moved on… until I realised that the shared drives had been encrypted as well. By being slack on securing my personal devices, I’d potentially exposed a work machine (thankfully the shared files were installers for stuff like Wireshark). Potentially a more motivated attacker could have jumped machines, leveraged my VPN and got into my work network. In other words it could have been much worse.
One of the popular terms that I’ve learnt since becoming a Cyber Champion is “Zero Trust” and building a “Zero Trust Architecture”. This is about building solutions on the assumption that your outer layers of security should be compromised so you should secure all communications within your system. I could ramble on more about this but I want to stress that this applies not just to what we build, but to how we work.
If an attacker managed to get into one of my work machines they could steal our source code. This would have IP impacts but also would allow an attacker to understand our solutions and find any vulnerabilities. Simply encrypting all of our machines to stop them from working could be huge. Imagine if you have all engineers locked from doing work, or pushing changes to the repo. How much money does it cost to have developers sit in the kitchen having a coffee for a week whilst you try and restore things?
These types of attacks are very common in some sectors such as Government organisations, from “city hall” to police to health, but as software developers we’re viable targets as well.
So hopefully I’ve scared you a little. It is quite possible that you could expose your company and cause them massive damage.
However there are good things that we can be doing to protect ourselves.
My work uses security solutions that, as engineers, we usually deride for blocking us from working and sometimes look to work around. But they are important. If you can understand why they are there (see above), it is important to find how you can work alongside them, as opposed to against them.
Firewalls are an important start. All too often when we’re having communication issues with devices or services on our VMs we’ll ask “have you tried turning the firewall off?”. If you do this, only do it for a minute to prove whether firewall rules are an issue or not, then enable it again. It is important that machines on your network are only able to use the protocols and ports that you need them to use.
As tempting as it can be to download a tool to help with a job, for example I downloaded a tool to help me access the memory of an application to help with work, we need to consider the security implications. Could it be doing something malicious? Could an attacker use it to perform a malicious act? This could be a vulnerability in the application, or simply it would be a wonderful little tool for an attacker to use. Look at using software that has been approved by your organisation and uninstalling anything non-essential once it has served its purpose.
The other big area that so many of us fall down is on passwords. It is well known that a lot of people use things like Admin/Admin1234 or TestUser/Test1234 for their passwords in test environments. Similarly when there is a default login like admin/password, many people out there don’t change them.
I still remember being on a remote support session and without thinking I just entered the default credentials for an application and successfully logged in. Afterwards I was politely informed to always ask the customer to enter the credentials and it was also fed back to the customer to change their password.
p.s. don’t have default credentials in your application or at least force them to be changed after the first login.
It is important that we make sure that every account we create, especially admins, have a good & strong password that is unique. Don’t go replacing Admin1234 with My!W0rkN@m3 for everything on the network. Yes it is more secure but if someone got/guessed that password, they may have untold access to your work’s network.
So how do I remember them all? I do use wikis for some shared resources but it is better when we use a shared password manager that in itself has access permissions. I also have my own system for creating passwords, which for obvious reasons I won’t share, but that means I don’t need to remember what my passwords are, only what logic I used to come up with it.
The best solution however is to use domain accounts. This allows us to restrict access to machines and also use good, secure passwords. Obviously being part of a big corporation we don’t have permission to be adding short lived VMs to the company domain and making ourselves admins when we want, so what we’ve done is set up our own domain server that has no trust relationship with the main network.
There is another thing that we need to consider and that is access permissions. I doubt I’m alone in running most of my services as the Local Service admin account, using “Run as Administrator” or “sudo” commands when I want stuff to be working. A common example is when your service needs to write to Program Files. As a standard user it will fail but run as admin and it will work, right? This can be dangerous as there’s things like “Remote OS Command Injection” where an attacker could leverage a vulnerability to execute a command as an admin such as formatting a disk, or disabling security.
To prevent this it is best to have dedicated accounts for things that need to run with elevated privileges. For example, let’s say that you’ve downloaded a NTP service to keep your machines in sync. Rather than running as admin, the installer may help set up an account that is dedicated just to just what it needs to manage NTP – or you could set up your own account with a bit of Googling.
This is an area where mobile does seem better than desktops. For example if I downloaded an app that wanted to access my calls, I get a specific prompt asking for this permission. On Windows or Linux I’ll probably get an error when it tries and fails. After re-running as admin, it now works and exposes the application to way more than calls.
And finally – if any of this seems like too much effort to maintain then there is an alternate approach (depending on your setup). Create an isolated network for your testing where there’s no internet access and you need to physically connect to it.
It may seem like a pain but honestly, it is important that we consider the security implications of how we work just as much as the security of our products. After all, you don’t want to be the one that brings your company to a grinding halt.
Disclaimer: I have no idea on what caused the CD Projekt Red hack. It may have been something that I’ve discussed, it may not. I did not intend to speculate or criticise. I picked them as the example because I loved Cyberpunk 2077 (completed it 6 or 7 times). Please don’t sue me guys!
You don’t need to understand code to make use of dump files.
One tool that I’ve frequently used throughout my testing career (and also development) is WinDbg. I was a little surprised when I realised that very few other people use it so I thought that I’d share a little about why I use it and how to get going.
What can you do?
See the code path in a crash dump
View data in memory
View threads that are running when software is in a hang
Many more things that I’ve yet to try
This can be especially useful if you’re tasked with reproducing a crash reported by a customer and (as is unfortunately common) they say “I wasn’t doing anything”.
What you’ll need:
WinDbg or WinDbg Preview
Access to symbols files for your software (developers can probably help set you up).
A dump file that you want to look at (more on this later)
This is part of Debugging Tools for Windows. You can download it for free from Microsoft. There’s a newer “preview” version that is quite neat plus the older one that I’m more accustomed to using as part of the Windows 10 SDK. Both are linked from here:
If the link is broken, Google for WinDbg and you should find it.
Obtaining dump files
Hopefully your software outputs crash dumps but if not, you can add some registry keys to ensure that they are generated in a known location. Even if your software does create minidumps, you may value full dumps more:
Open regedit and access: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\Windows Error Reporting\LocalDump
If you want to create a dump file of running software, for example to inspect memory or dig into a hang then you can use task manager. Just right click on the process and click “Create dump file”.
Note that if you are using a 32bit application then you’ll need the 32bit task manager, e.g. c:\windows\syswow64\Taskmgr.exe
There’s also tools out there that will generate dump files on demand.
Symbols
The next thing that you’ll need to do is setup symbols path. These will help turn the 0s and 1s in a minidump into more readable strings. Create yourself a folder for the symbols, for example c:\symbols. Then in WinDbg you’ll need to set the path. In the old version open the File menu and you should see an option. For the Preview version go to Settings then Debugging.
You may have to add a few paths in there but hopefully you get the idea.
Analysing crash dumps to get a call stack
Now on to the juicy part, analysing a crash dump. You can open it from the File menu.
From the View menu, you should be able to see the option for a stack / call stack. Bring that up whilst the dump is being loaded.
Now run the following commands (they take a few minutes):
.ecxr
!analyze -v
This should tell you a chunk of information about the crash. Based on this you can
An example of using this information
When looking for an example I found a crash dump from a game that I made many years ago. I have absolutely no idea what might of caused it so hopefully now I can figure out why.
My WinDbg analysis included the following:
System.NullReferenceException
This tells me that it tried using an object that didn’t exist. Either it hasn’t been set or has been deleted but is still in use.
From this I can tell that the game was being closed. It has happened when unloading content so likely its tried to . It may be possible dig deeper. As you gain more skill with the software it is possible to learn more about what was in memory to understand at exactly what point it crashed.
And here’s the key part
If I was trying to reproduce this crash, I can take the knowledge learnt from the crash dump to guide how I will try and get to the bottom of it. Unfortunately the example dump I picked is a tricky one but I could maybe come up with something like “Explore exiting the game with different assets loaded to discover the source of the crash”.
A 10-20 snoop in the dump file might save me a huge chunk of time in trying to reproduce a crash. Obviously I can’t share real examples from my professional life in any detail but knowing that mouse over a control caused a “random” crash or that the software crashed after hitting “Save” and the top of the call stack was “MyApp!MyApp.FileIo.SaveFile.ApplyTextOverlay” then I can focus on that area.
There’s loads more that you can do but hopefully this has been useful!